 切换行业
切换行业

4月24日,在2024中国石油石化企业信息技术交流大会暨油气产业数字化转型高峰论坛上,中国工程院院士、中国石油勘探开发研究院教授刘合进行了主题为《油气行业AI大模型发展的展望》的演讲。

刘合院士表示,大模型必将推动油气行业新质生产力发展,国内油气行业大模型研发刚刚起步,展现出巨大应用潜力,但应切忌冒进,要从数据、算力、算法等方面做好基本功。

大模型的概念及发展现状
人工智能大模型目前没有一个准确的定义,国外通常叫基础模型(foundation model),国内通常叫大模型,通常是指用多模态数据(图像、文本、表格数据等)预训练、包含几十甚至上千亿参数量的深度学习模型。
大模型最初指的是大语言模型(Large Language Model, LLM),后来发展了视觉大模型(Large Vision Model, LVM)、多模态大模型等。2022年7月李飞飞等100余名学者联名发表文章《On the Opportunities and Risks of Foundation Models》,正式提出基础模型(foundation model)的概念,2022年OpenAI推出历时八年研发而成的ChatGPT,将大模型推向新一轮热潮。
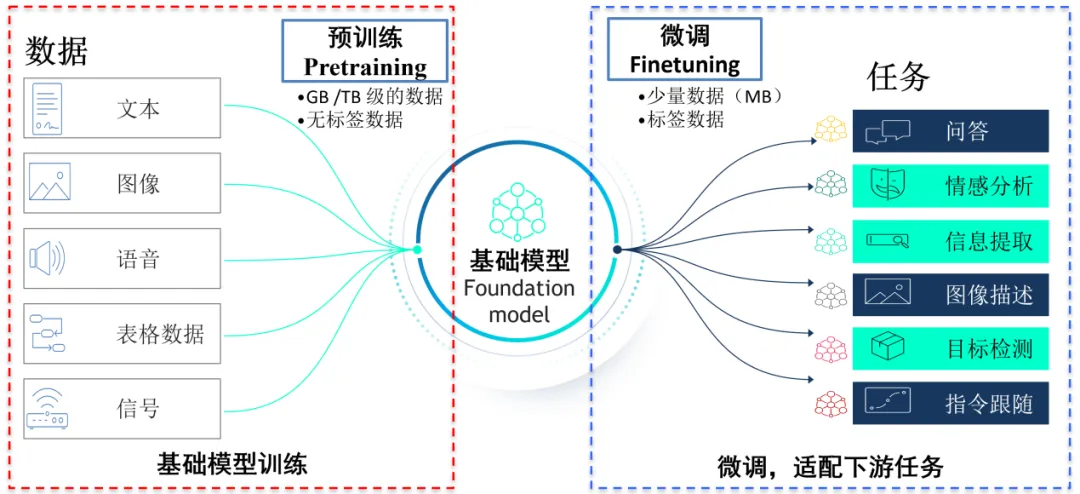
什么是大模型呢?
刘合院士认为可以从以下几个方面来判定大模型:参数量、使用数据量、计算资源、泛化能力、适应性、灵活性、性能指标等。
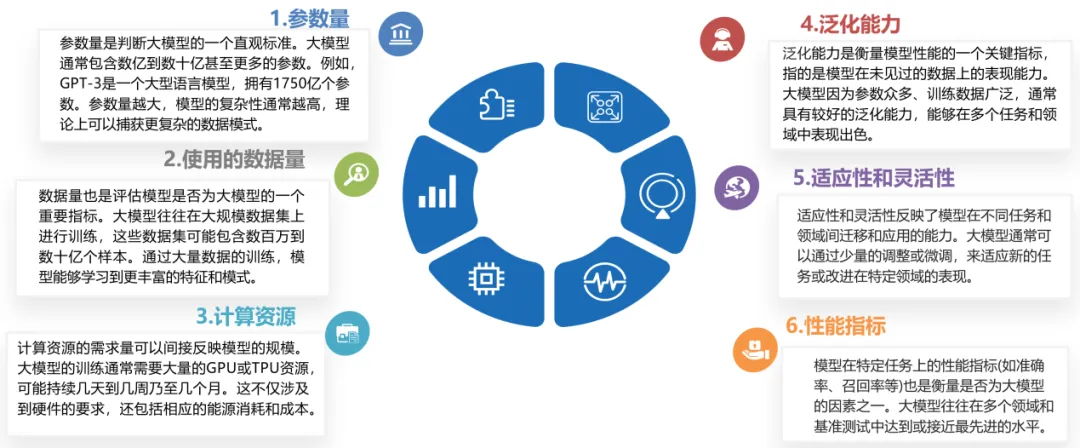
刘合院士用科普的语言介绍了几个大模型常用术语。比如大语言模型、视觉大模型、多模态大模型。大语言模型好比是盲人,只能分析处理语言;视觉大模型好比是聋哑人,只能分析处理图像和视频;多模态大模型好比是正常人,可以处理语言、图像、视频、文字等多模态数据。如果把训练大模型比喻为做麻辣香锅的话,那么预训练相当于做麻辣香锅的底料,微调相当于是自己买食材。
大模型相比于传统AI,表现出了泛化性(Generalization)、通用性(Generality)、涌现性(Emergency)三个特征。
泛化性是指模型在未见过的数据上的表现能力,大模型的泛化能力更强,能够适应和正确处理新的、不同的或未见过的情况。
通用性是指模型处理各种不同任务的能力,大模型具有高通用性,能够在广泛的任务类型上表现出良好的性能,不需要对每个新任务进行特别定制或重新训练。
涌现性是指当模型达到一定的规模和复杂度时,它能够展示出一些在小规模或较简单模型中未曾出现的新能力或行为。
大模型在垂直领域的应用情况
总体来说,我国大模型产业跟国际比,还有一定差距。以OpenAI的chatGPT为例,看一下国内外大模型的差距。OpenAI只做大模型,而且是从八年前就只研发这一件事,此外还聘请了顶尖级的算法专家,也在数据、算力、算法等方面做了大量扎实的工作。对比来看,咱们国内的大模型企业大部分都还是根基尚浅。所以我们要正视差距、理性认识不足,大步追赶。国家层面对大模型发展也给予了极大的关注和支持,通过政策倾斜和资金投入,大力发展大模型产业。
大模型在垂直领域的应用可以分为三个等级:通用基础模型、行业基础模型、场景模型。通用大模型基本是由一些大型IT公司和有实力的创业公司来研发,比如国外的OpenAI、DeepMind、谷歌、苹果等,国内的阿里、百度、腾讯、百川智能等。行业大模型是在通用大模型的基础上,加入行业数据和专家经验,研发的大型预训练模型。场景模型是利用通用大模型或者行业大模型研发的解决具体业务场景的模型。

近一年来,大模型的垂直应用已经在法律、医疗、城市建设等多个行业迅速展开,并展现出巨大的潜力和价值。油气行业人工智能大模型应用刚刚起步,可以分为大语言模型、视觉大模型/多模态大模型两个方面的垂直应用。跟通用行业一样,油气行业在大语言模型方面应用最快,如23年SPE年会上的PetroQA等。视觉大模型和多模态大模型刚刚开始探索,如DDE和之江实验室联合推出的GeoGPT。GeoGPT是为了解决地学科研瓶颈的专有大模型;使用了丰富的地学专有语料。
大模型研发的关键要素
推动大模型发展的关键因素有三个:数据、算力、算法。
数据是大模型应用的基石!
算力是大模型应用的保障!
算法是大模型应用的工具!

大模型训练是一项非常复杂的系统工程,训练量大、数据量大、时间长。大模型通常包含十亿至数百亿的参数,使用了海量数据,因此需要强大的算力和优化算法来训练,训练时间也比较长,即大模型的训练成本很高。
数据方面,通用基础模型很多是在开源数据集上训练的,使用的数据量大、泛化性强。几个公开数据集也为通用基础模型的训练提供了基础。油气行业的数据非常复杂,且由于采集、存储模式等原因,历史数据的数据质量问题较为严重。数据质量是影响油气行业大模型应用的关键。
算力方面,训练大模型需要GPU算力,为什么不用CPU呢?因为大模型训练需要很多重复计算。CPU,中央处理器,它擅长的是少量复杂逻辑和决策的任务;GPU,图形处理器,它擅长的是重复、大量计算。举一个例子,CPU是一个数学系毕业的高材生,能计算各种艰深复杂的问题,GPU就像是汇集了一万个只会1+1=2的小学生,能以最快的速度处理海量简单重复的问题,这正是训练人工智能最需要的能力,通过对庞大数据的学习、分析、推理,让机器像人类那样解决问题。
目前几个知名的通用模型都是用了很多算力才训练出来的,比如LLaMA 2,70B的模型用了1.6万块A100;GPT 3,175B的模型,用1000块A100训练22天。但是,我国油气行业普遍不具备基础模型的训练能力,只能是微调。
算法方面,这一轮大模型的发展很大程度上是少数几个顶尖人才推动的算法上的突破。但算法本质上还是一个工具,一是算法的性能高度依赖于数据的质量和数量;二是算法泛化能力有限;三是算法可能受到攻击。油气行业在大模型算法方面普遍缺乏自主可控,且油气行业大模型应用的定位应该是如何用大模型算法支撑油气主营业务,而不是跟互联网企业去卷大模型算法。
未来应用展望
ChatGPT推出以后,油气行业对大模型的兴趣越来越大。但油气行业大模型应用面临很多问题和挑战。
一是数据的问题。油气行业相比于通用行业,存在采集成本高、多解性、样本少、多模态等问题,如何以大模型应用为契机,推动数据治理这是首先要考虑的工作。
二是算力的问题,现在我们没有训练大模型所需要的算力,那怎么办呢?是投入大笔资金去买?还是租赁别人的算力?自己建设的话,怎么建、谁来建、怎么用?租赁的话怎么保证数据安全和隐私保护?
三是算法的问题。OpenAI在超强算力、超大数据、高级人材的加持下,投入8年才研发ChatGPT,ChatGPT有时候还不够准确,还在不断迭代升级。这是一个系统工程,目前油气行业要做好研发自己大模型能力的评估,强化顶层设计、量身定做、量力而行。
四是“百模大战”扑朔迷离,油气行业如何理性认识和应用大模型?国内大模型产业面临“百模大战”的局面,在一定程度上干扰了油气行业大模型应用的战略决策,如何理性认识和应用大模型是我们应该深入思考的问题。

五是版权的问题。现在总体来看,开源的模型性能比不上闭源的,同时,一部分开源模型不是真正意义上的开源,开源了也不等于可以商用,都有很多限制条件。油气行业应用大模型要谨慎处理版权问题。
虽然面临很多问题和挑战,但大模型必将推动油气行业新质生产力发展,油气行业大模型应用前景广阔。
一是场景模型和数据质量好的L2行业基础模型先行实施,解决油气业务需求。大模型行业垂直应用时可以分成通用基础模型、行业基础模型、场景模型3个等级。油气行业又细分成了L1、L2两个级别的行业基础模型。油气行业大模型近期可行的是场景模型和部分数据质量好的L2行业基础模型,不要自己研发通用基础模型,L1级别的行业基础模型也建议慎重论证。因为基础模型的训练代价太大,成本太高。
二是以大模型应用为契机,加强数据全生命周期管理,提升数据治理能力。行业应用的关键是数据,我们油气行业在大模型方面的核心竞争力是“行业数据”,要做好“训练样本库”的基本功。以打造行业大模型为契机,提升数据质量,构建大模型应用所需要的“样本库”
三是以油气大模型为契机,推动融合算力建设。算力建设的方式,建议是租赁和自建相结合,统筹考虑通算、智算、超算设施建设规划,突出打造以智算为重点的融合算力设施建设。
四是分布合理、有序实施油气行业大模型,切实解决油气业务痛点
要理性认识到:大模型不是万能的!一个模型不能解决油气勘探开发的所有事情,近期可行的场景是有海量高质量数据,建模不依赖其他无法输入模型的知识,如岩心分析的行业基础模型。
五是以大模型应用为契机,加强“AI+能源”复合团队建设,推动大模型技术栈自主可控。大模型自己干是搞不成的,要联合大的IT企业、高校,建立一个良好研发生态。
大模型必将推动
油气行业新质生产力发展
未来可期,但道阻且长
油气行业大模型应用需要
从数据、算力、算法等方面
做好扎实工作
切忌冒进、要稳步实施





 正在加载...
正在加载...


